Supervised vs. Unsupervised Learning: Key Differences
There are two main approaches to machine learning: supervised and unsupervised learning. The main difference between the two is the type of data used to train the computer. However, there are also more subtle differences.
Machine learning is the process of training computers using large amounts of data so that they can learn how to independently complete tasks associated with human intelligence (e.g., translating, making recommendations).
Two key aspects of machine learning are data and algorithms. Any type of information that can be used as an input by a computer (text, images, audio etc.) is data. An algorithm is a set of instructions given to a computer so that it processes the data and learns from it. Data and algorithms (combined through training) make up the machine learning model.
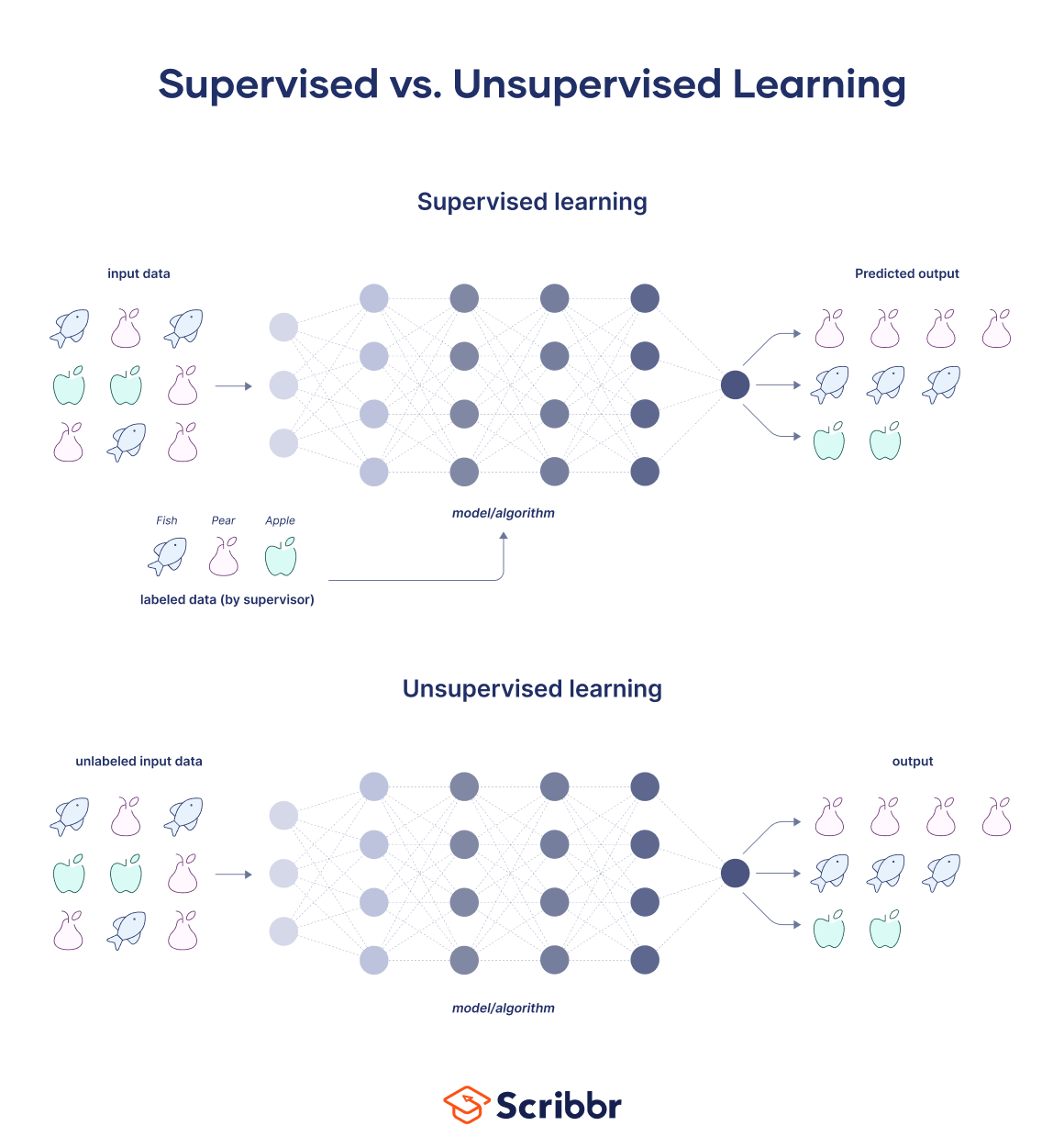
Table of contents
- What is supervised learning?
- Supervised machine learning methods
- What is unsupervised learning?
- Unsupervised machine learning methods
- Differences between supervised and unsupervised learning
- Semi-supervised learning
- Other interesting articles
- Frequently asked question about supervised and unsupervised learning
What is supervised learning?
Supervised learning involves a human “teacher” or “supervisor.” Their role is to feed the computer with labeled data or examples consisting of a combination of problems and solutions.
With supervised learning, a human expert would go through a database of images and label each one of them as either “cat” or “dog.” Then, the expert would feed this labeled dataset into the computer, and the computer would process the images one by one to learn by itself which characteristics constitute a cat and which ones constitute a dog (similar to how toddlers learn).
Once the training is done, the computer is able to recognize new images of cats and dogs.
In supervised learning, the aim is to make sense of data within the context of a specific question or problem (such as “identify images of cats”). By giving the computer lots of examples (in this case, images) along with the correct answers (i.e., whether it’s a dog or a cat in the image), the computer learns to correctly identify new data.

Supervised machine learning methods
Supervised machine learning is used for two types of problems or tasks:
- Classification, which involves assigning data to different categories or classes
- Regression, which is used to understand the relationship between dependent and independent variables
Both classification and regression are used for prediction and work with labeled datasets. However, their difference lies in the nature of the output they aim to predict. For example, predicting whether an employee will get a raise is a classification problem, while predicting how much their salary ought to increase is a regression problem.
Classification
Classification is used to categorize input data into predefined classes or categories. By training with labeled data, the computer learns to recognize and differentiate various features or characteristics associated with each class.
For example, in image classification, the goal may be to identify objects in an image. Similarly, classification can be used to predict discrete outcomes, like determining whether it will rain on a given day.
Examples of classification problems include:
- Language detection
- Recognition of handwritten characters and numbers
- Fraud detection (e.g., suspicious bank transactions)
- Categorizing customer feedback as positive or negative
- Disease diagnosis
- Email spam detection
Regression
Regression is a type of classification where we forecast a number instead of a category.
With regression, the predicted outcomes are real values, such as the expected price of a house (based on information like square footage or location). Regression can assist companies with sales predictions by considering variables such as weather, social media presence, or inbound tourists.
Examples of regression problems include:
- Predicting the future value of a stock
- Revenue forecasts for a business
- Energy consumption forecasting
- Demand prediction
- Credit risk assessment
- Salary prediction
In both regression and classification, the goal is to find specific relationships or patterns in the input data that allow the computer to effectively generate correct output data.
For example, if we want to predict customer satisfaction with a certain product, we can assign each satisfaction level a number from 1 to 10, or we can create specific categories, such as “very satisfied,” “satisfied,” etc.
In other words, we could approach this either as a regression task (i.e., predicting the numerical satisfaction rating), or a classification task (i.e., assigning each customer to the appropriate satisfaction category based on their predicted satisfaction level).
The choice between the two depends on the nature of the data, the problem formulation, and the type of output or solution we want.
What is unsupervised learning?
Unsupervised learning is used when there is no labeled data or instructions for the computer to follow. Instead, the computer tries to identify the underlying structure or patterns in the data without any assistance.
The company can take this raw data and apply an unsupervised learning algorithm to discover hidden patterns and similarities within the data.
The algorithm can group similar customers together based on shared characteristics, allowing for the identification of distinct segments that can inform future marketing campaigns (e.g., personalized recommendations).
Unsupervised learning is valuable for exploratory analysis, where the goal is to automatically discover hidden patterns in data.
Unsupervised machine learning methods
Unsupervised learning is used for three main tasks:
In each of these tasks, we want to discover the inherent structure of our data for which no predefined categories or labels exist.
Clustering
Clustering is a machine learning technique for grouping unlabeled data based on their similarities or differences. Clustering helps us find patterns in the data even if we don’t know what we are looking for.
Sorting customers into different segments, for example, is a clustering problem: it involves discovering inherent groups in the data. Clustering is like dividing a pile of books per genre or topic, without knowing anything about those books in advance. You go through the books one by one and, if they are similar, put them in the same group.
Examples of clustering problems include:
- Recommendation systems: Grouping users or items with similar preferences or characteristics to make personalized recommendations for products, movies, or music
- Image compression: Reducing the size of an image by grouping similar pixels together
- Social network analysis: Identifying communities or groups within social networks based on connections and interactions between individuals
- Anomaly detection: Detecting abnormal behavior, such as network intrusions or suspicious bank transactions
Association
Association focuses on identifying co-occurrence or dependencies between items without the presence of predefined labels or outcomes.
Association analysis is commonly used to find interesting associations or rules (e.g., in market basket analysis where the goal is to identify frequently co-purchased items, such as goods commonly bought together in a grocery store).
The result or output of association analysis is usually in the form of “if X, then Y,” indicating that when product X appears (e.g., cappuccino), there is a high likelihood of Y also being present (e.g., a muffin).
Examples of association problems include:
- Recommendation systems: Generating personalized recommendations based on cross-category purchase correlations (“frequently bought together” recommendations)
- Tailored marketing campaigns: Identifying specific product or service combinations that are commonly associated with particular groups (based on age, occupation, etc.)
- Medical analytics: Uncovering correlations between symptoms, treatments, and patient outcomes to improve diagnosis or treatment plans
Dimensionality reduction
Dimensionality reduction is a technique used in machine learning when we have a lot of information to handle. It helps by reducing the number of inputs or features while still keeping the important parts of the data. This makes the data easier to work with and understand. For example, it can clean up images to make them look better.
Examples of dimensionality reduction problems include:
- Image and video processing: Compressing and enhancing images and videos, reducing the storage space required while preserving important visual information
- Genetic research: Making sense of large amounts of genetic data. By reducing the complexity of the data, scientists can analyze and interpret genetic data
- Document classification: Making online journal databases more user-friendly. Relevant features can be extracted from the content of the articles, allowing for more efficient organization within the database
Differences between supervised and unsupervised learning
The differences between supervised and unsupervised learning are summarized in the table below:
| Supervised learning | Unsupervised learning | |
|---|---|---|
| Data | Uses labeled data with known answers or outputs | Processes unlabeled data. There are no predefined answers (i.e., no desired output is given) |
| Goals | To make a prediction (e.g., the future value of a house) or a classification (e.g., correctly identify spam emails) | To explore and discover patterns, structures, or relationships in large volumes of data |
| General tasks | Classification, regression | Clustering, dimensionality reduction, association learning |
| Can be applied to | Sentiment analysis, stock market prediction, house price estimation | Medical image analysis, product recommendations, fraud detection |
| Human supervision | Requires human intervention to provide labeled data for training | Does not require human intervention/explicit guidance |
| Accuracy | Tends to have higher accuracy because it learns from labeled examples with known answers | Accuracy evaluation is harder and more subjective because there are no correct answers |
Semi-supervised learning
Semi-supervised learning is a hybrid approach that combines the strengths of supervised and unsupervised learning in situations where we have relatively little labeled data and a lot of unlabeled data.
The process of manually labeling data is costly and tedious, while unlabeled data is abundant and easy to get. For this reason, instead of labeling the whole dataset, we can label only a part of the dataset.
The combination of the two data types in one dataset allows machine learning algorithms to learn how to label data independently. More specifically, semi-supervised learning algorithms use the labeled data to learn patterns and relationships, which are then applied to unlabeled data to make predictions or classifications.
In this way, semi-supervised learning addresses some key challenges of the two other methods:
- Unlike unsupervised learning, semi-supervised learning can handle many types of problems, ranging from classification and regression to clustering or association.
- Unlike supervised learning, semi-supervised learning needs small amounts of labeled data, so it involves less data preparation.
Choosing between any of the three learning methods depends on the type and quality of the available data, as well as the nature of the problem to be solved (i.e., whether it is well-defined or open-ended).
Other interesting articles
If you want to know more about ChatGPT, AI tools, fallacies, and research bias, make sure to check out some of our other articles with explanations and examples.
ChatGPT
Fallacies
Frequently asked question about supervised and unsupervised learning
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Nikolopoulou, K. (2023, December 29). Supervised vs. Unsupervised Learning: Key Differences. Scribbr. Retrieved July 9, 2026, from https://www.scribbr.com/ai-tools/supervised-vs-unsupervised-learning/
