What Is Machine Learning? | A Beginner's Guide
Machine learning (ML) is a branch of artificial intelligence (AI) and computer science that focuses on developing methods for computers to learn and improve their performance. It aims to replicate human learning processes, leading to gradual improvements in accuracy for specific tasks. The main goals of ML are:
- classifying data based on models that have been developed (e.g., detecting spam emails).
- making predictions regarding some future outcome on the basis of these models (e.g., predicting house prices in a city.)
Machine learning has a wide range of applications, including language translation, consumer preference predictions, and medical diagnoses
What is machine learning?
Machine learning is a set of methods that computer scientists use to train computers how to learn. Instead of giving precise instructions by programming them, they give them a problem to solve and lots of examples (i.e., combinations of problem-solution) to learn from.
For example, a computer may be given the task of identifying photos of cats and photos of trucks. For humans, this is a simple task, but if we had to make an exhaustive list of all the different characteristics of cats and trucks so that a computer could recognize them, it would be very hard. Similarly, if we had to trace all the mental steps we take to complete this task, it would also be difficult (this is an automatic process for adults, so we would likely miss some step or piece of information).
Instead, ML teaches a computer in a way similar to how toddlers learn: by showing the computer a vast amount of pictures labeled as “cat” or “truck,” the computer learns to recognize the relevant features that constitute a cat or a truck. From that point onwards, the computer can recognize trucks and cats from photos it has never “seen” before (i.e., photos that were not used to train the computer).

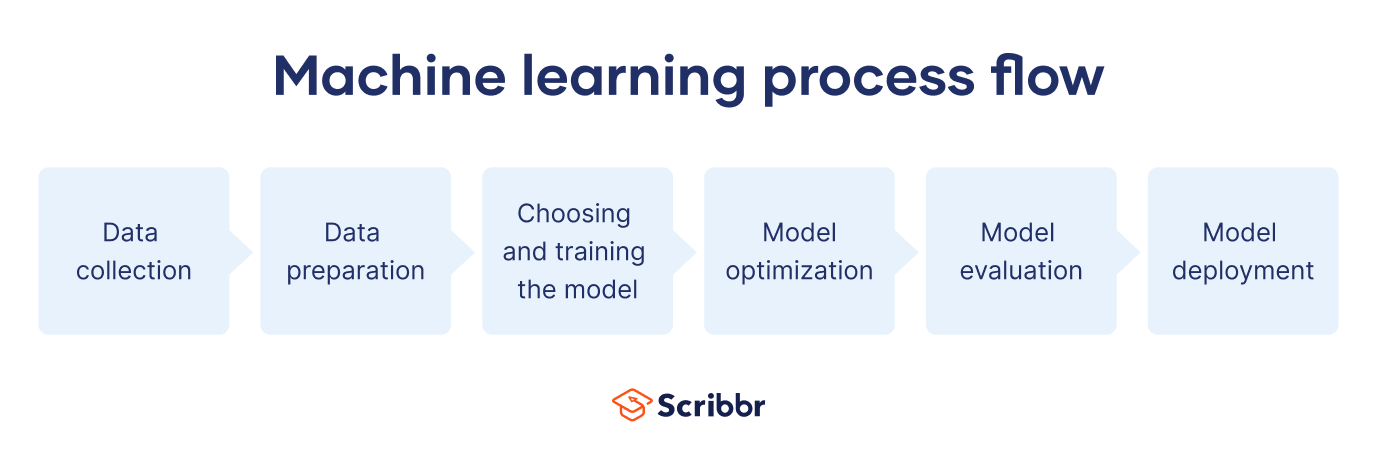
How does machine learning work?
Performing machine learning involves a series of steps:
- Data collection. Machine learning starts with gathering data from various sources, such as music recordings, patient histories, or photos.This raw data is then organized and prepared for use as training data, which is the information used to teach the computer.
- Data preparation. Preparing the raw data involves cleaning the data, removing any errors, and formatting it in a way that the computer can understand. It also involves feature engineering or feature extraction, which is selecting relevant information or patterns that can help the computer solve a specific task. It is important that engineers use large datasets so that the training information is sufficiently varied and thus representative of the population or problem.
- Choosing and training the model. Depending on the task at hand, engineers choose a suitable machine learning model and start the training process. The model is like a tool that helps the computer make sense of the data. During training, the computer model automatically learns from the data by searching for patterns and adjusting its internal settings. It essentially teaches itself to recognize relationships and make predictions based on the patterns it discovers.
- Model optimization. Human experts can enhance the model’s accuracy by adjusting its parameters or settings. By experimenting with various configurations, programmers try to optimize the model’s ability to make precise predictions or identify meaningful patterns in the data.
- Model evaluation. Once the training is over, engineers need to check how well it performs. To do this, they use separate data that were not included in the training data and therefore are new to the model. This evaluation data allows them to test how well the model can generalize what it has learned (i.e., apply it to new data it has never encountered before). This also provides engineers with insights for further improvements.
- Model deployment. After the model has been trained and evaluated, it is used to make predictions or identify patterns in new, unseen data. For example, we use new images of vehicles and animals as input and, after analyzing them, the trained model can classify the image as either “truck” or “cat.” The model continues to adjust automatically to improve its performance.
It is important to keep in mind that ML implementation goes through an iterative cycle of building, training, and deploying a machine learning model: each step of the entire ML cycle is revisited until the model has gone through enough iterations to learn from the data. The goal is to obtain a model that can perform equally well on new data.
Data is any type of information that can serve as input for a computer, while an algorithm is the mathematical or computational process that the computer follows to process the data, learn, and create the machine learning model. In other words, data and algorithms combined through training make up the machine learning model.
Types of machine learning models
Machine learning models are created by training algorithms on large datasets.There are three main approaches or frameworks for how a model learns from the training data:
- Supervised learning is used when the training data consist of examples that are clearly described or labeled. Here, the algorithm has a “supervisor” (i.e., a human expert who acts like a teacher and gives the computer the correct answers). The human expert has already prepared the data and labeled them, for example, into pictures of trucks and cats, which the algorithm uses to learn. Since the answers are included in the data, the algorithm can “see” how accurate its answers are and improve over time. Supervised learning is used for classification tasks (e.g., filtering spam emails) and prediction tasks (e.g., the future price of a stock).
- Unsupervised learning is used when the training data is unlabeled. The aim is to explore and discover patterns, structures, or relationships in the data without specific guidance. Clustering is the most common unsupervised learning task. It is a form of classification without predefined classes. It involves categorizing data into classes based on features hidden within the data (e.g., segmenting a market into types of customers). Here, the algorithm tries to find similar objects and puts them together in a cluster or group, without human intervention.
- Reinforcement learning (RL) is a different approach where the computer program learns by interacting with an environment. Here, the task or problem is not related to data, but to an environment such as a video game or a city street (in the context of self-driving cars). Through trial and error, this approach allows computer programs to automatically determine the best actions within a certain context to optimize their performance. The computer receives feedback in the form of reward or punishment based on its actions and gradually learns how to play a game or drive in a city.
Finding the right algorithm
Algorithms provide the methods for supervised, unsupervised, and reinforcement learning. In other words, they dictate how exactly models learn from data, make predictions or classifications, or discover patterns within each learning approach.
Finding the right algorithm is to some extent a trial-and-error process, but it also depends on the type of data available, the insights you want to to get from the data, and the end goal of the machine learning task (e.g., classification or prediction). For example, a linear regression algorithm is primarily used in supervised learning for predictive modeling, such as predicting house prices or estimating the amount of rainfall.
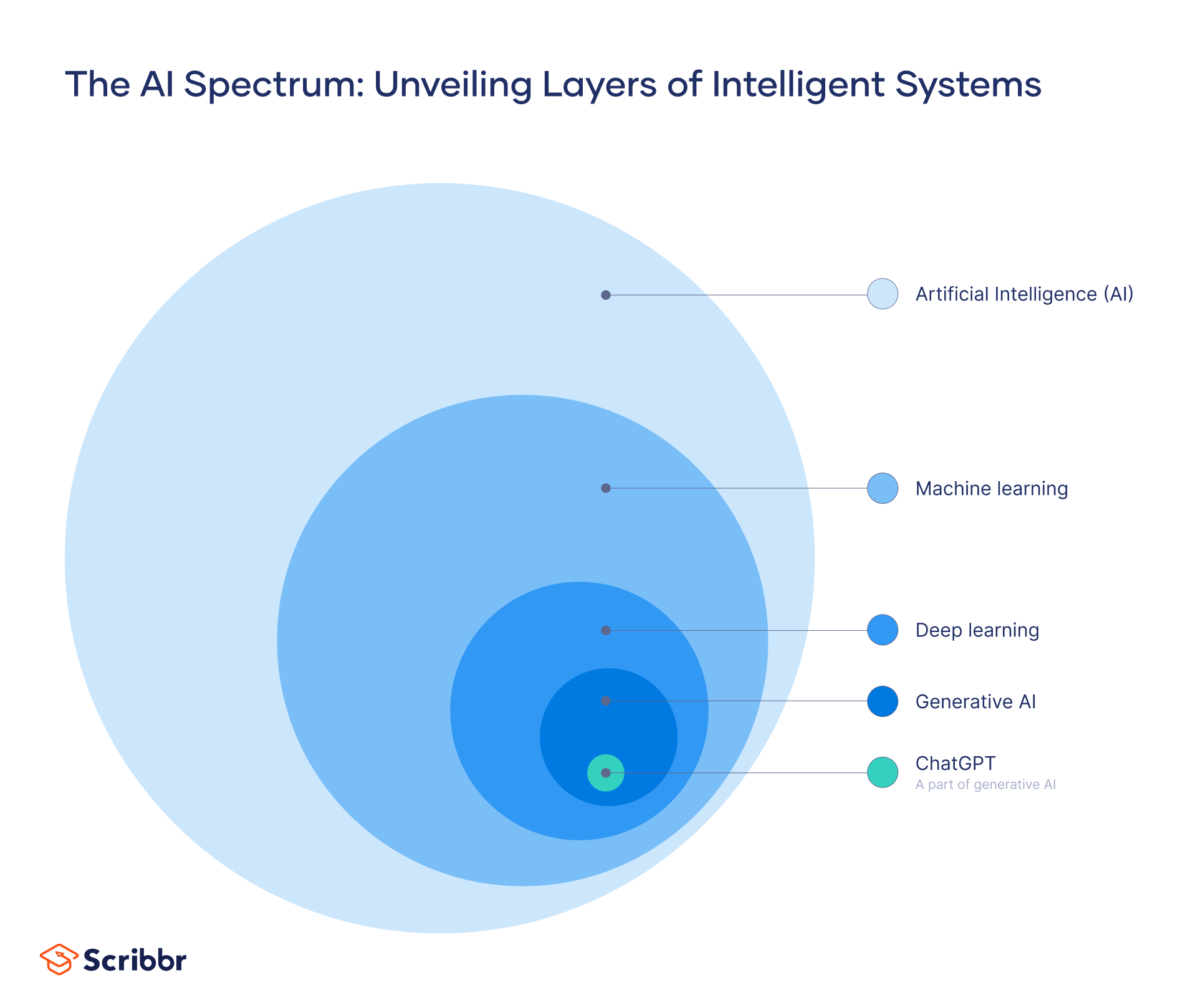
Machine learning vs. deep learning
Machine learning and deep learning are both subfields of artificial intelligence. However, deep learning is in fact a subfield of machine learning. The main difference between the two is how the algorithm learns:
- Machine learning requires human intervention. An expert needs to label the data and determine the characteristics that distinguish them. The algorithm then can use these manually extracted characteristics or features to create a model.
- Deep learning doesn’t require a labeled dataset. It can process unstructured data like photos or texts and automatically determine which features are relevant to sort data into different categories.
In other words, we can think of deep learning as an improvement on machine learning because it can work with all types of data and reduces human dependency.
Advantages & limitations of machine learning
Machine learning is a powerful problem-solving tool. However, it also has its limitations. Listed below are the main advantages and current challenges of machine learning:
Advantages
- Scale of data. Machine learning can handle problems that require processing massive volumes of data. ML models can discover patterns and make predictions on their own, offering insights that traditional programming can’t offer.
- Flexibility. Machine learning models can adapt to new data and continuously improve their accuracy over time. This is invaluable when it comes to dynamic data that constantly changes, such as movie recommendations, which are based on the last movie you watched or what you are currently watching.
- Automation. Machine learning models eliminate manual data analysis and interpretation and ultimately automate decision-making.This applies to complex tasks and large amounts of data that human experts would never be able to process or complete, such as going through recordings from conversations with customers. In other cases, ML can undertake tasks that humans would be able to complete, such as finding an answer to a question, but never on that scale or as efficiently as an online search engine.
Limitations
- Overfitting and generalization issues. When a machine learning model becomes too accustomed to the training data, it cannot generalize to examples it hasn’t encountered before (this is called “overfitting”). This means that the model is so specific to the original data, that it might fail to correctly classify or make predictions on the basis of new, unseen data. This results in erroneous outcomes and less-than-optimal decisions.
- Explainability. Some machine learning models operate like a “black box” and not even experts are able to explain why they arrived at a certain decision or prediction. This lack of explainability and transparency can be problematic in sensitive domains like finance or health, and raises issues around accountability. Imagine, for example, if we couldn’t explain why a bank loan had been refused or why a specific treatment had been recommended.
- Algorithmic bias. Machine learning models train on data created by humans. As a result, datasets can contain biased, unrepresentative information. This leads to algorithmic bias: systematic and repeatable errors in a ML model which create unfair outcomes, such as privileging one group of job applicants over another.
Other interesting articles
If you want to know more about ChatGPT, AI tools, fallacies, and research bias, make sure to check out some of our other articles with explanations and examples.
ChatGPT
Fallacies
Frequently asked questions about machine learning
Sources in this article
We strongly encourage students to use sources in their work. You can cite our article (APA Style) or take a deep dive into the articles below.
This Scribbr articleNikolopoulou, K. (2023, August 04). What Is Machine Learning? | A Beginner's Guide. Scribbr. Retrieved July 23, 2026, from https://www.scribbr.com/ai-tools/machine-learning/
Theobald, O. (2021). Machine Learning for Absolute Beginners: A Plain English Introduction (3rd Edition).
