Published on
March 29, 2021
by
Lauren Thomas.
Revised on
June 1, 2023.
Grad school interviews are the last step of the application process, so congratulations for making it to this stage! Getting this far is a big accomplishment—graduate schools only conduct interviews with those applicants they are seriously considering accepting.
Grad schools conduct interviews to assess your “fit” with their program and faculty, as well as your interpersonal skills. In many cases, they may also be attempting to match you with a supervisor.
Before the interview, you should prepare by doing your research and reflecting on how you’ll answer these common questions.
In general, you’ll need to start preparing your application at least 6 months in advance of the deadline. Most application deadlines are about 7–9 months before the program’s start date.
Published on
November 27, 2020
by
Lauren Thomas.
Revised on
May 10, 2024.
The two most common types of graduate degrees are master’s and doctoral degrees:
A master’s is a 1–2 year degree that can prepare you for a multitude of careers.
A PhD, or doctoral degree, takes 3–7 years to complete (depending on the country) and prepares you for a career in academic research.
A master’s is also the necessary first step to a PhD. In the US, the master’s is built into PhD programs, while in most other countries, a separate master’s degree is required before applying for PhDs.
Master’s are far more common than PhDs. In the US, 24 million people have master’s or professional degrees, whereas only 4.5 million have doctorates.
Published on
October 30, 2020
by
Lauren Thomas.
Revised on
June 1, 2023.
Letters of recommendation often make or break a graduate school application. It’s important to think carefully about who to ask and how to do it.
Ideally, you should approach former supervisors who know you and your work well, and can advise you. Different programs require different types of recommendation letters, but the process of requesting them is similar.
Follow these five steps to guarantee a great recommendation, including program-specific tips and email examples.
Published on
October 2, 2020
by
Lauren Thomas.
Revised on
December 18, 2023.
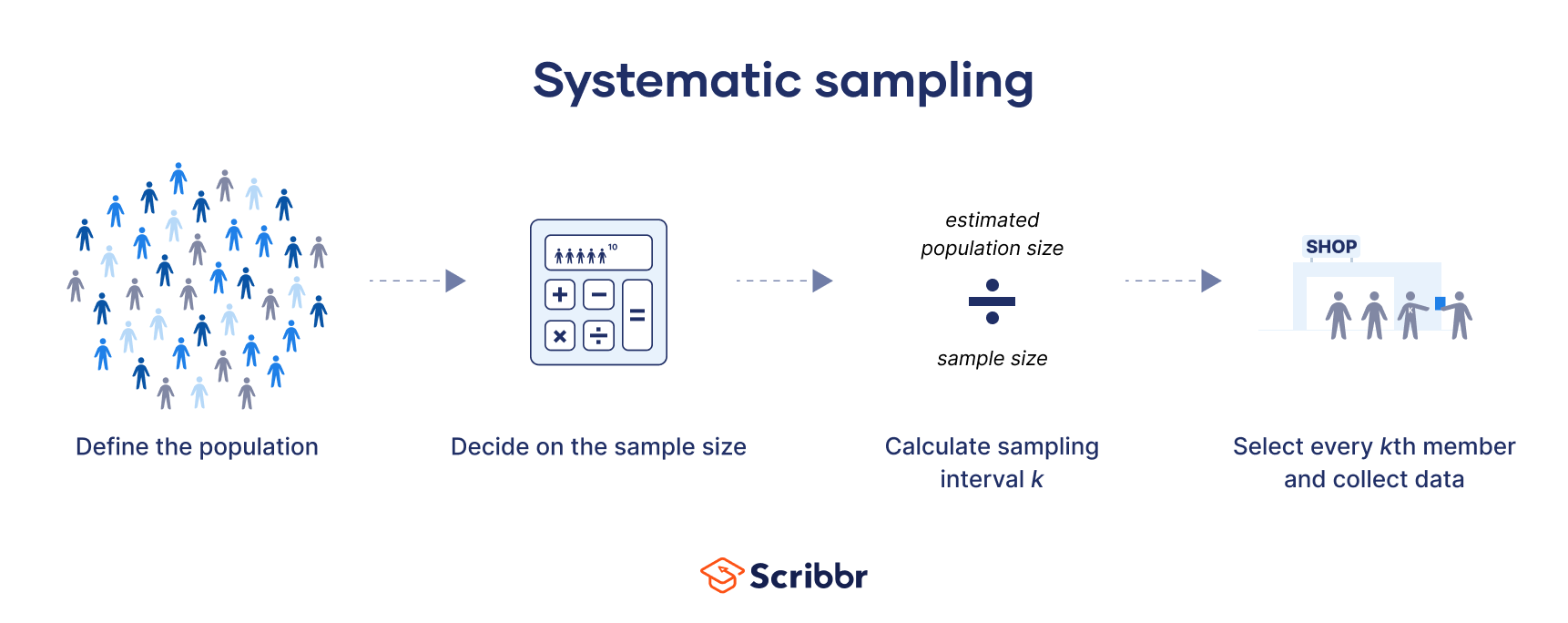
Systematic sampling is a probability sampling method in which researchers select members of the population at a regular interval (or k) determined in advance.
If the population order is random or random-like (e.g., alphabetical), then this method will give you a representative sample that can be used to draw conclusions about your population of interest.
Published on
September 18, 2020
by
Lauren Thomas.
Revised on
June 22, 2023.
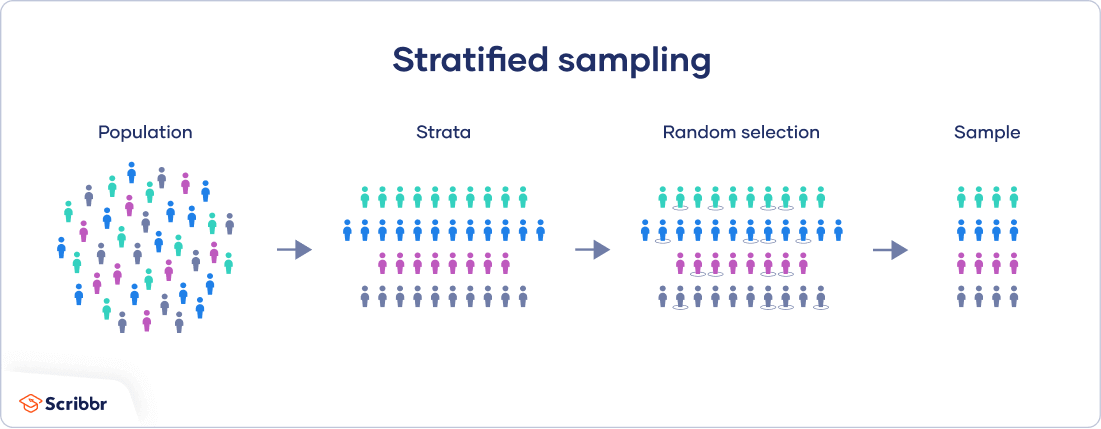
In a stratified sample, researchers divide a population into homogeneous subpopulations called strata (the plural of stratum) based on specific characteristics (e.g., race, gender identity, location, etc.). Every member of the population studied should be in exactly one stratum.
Researchers rely on stratified sampling when a population’s characteristics are diverse and they want to ensure that every characteristic is properly represented in the sample. This helps with the generalizability and validity of the study, as well as avoiding research biases like undercoverage bias.
Published on
September 7, 2020
by
Lauren Thomas.
Revised on
June 22, 2023.
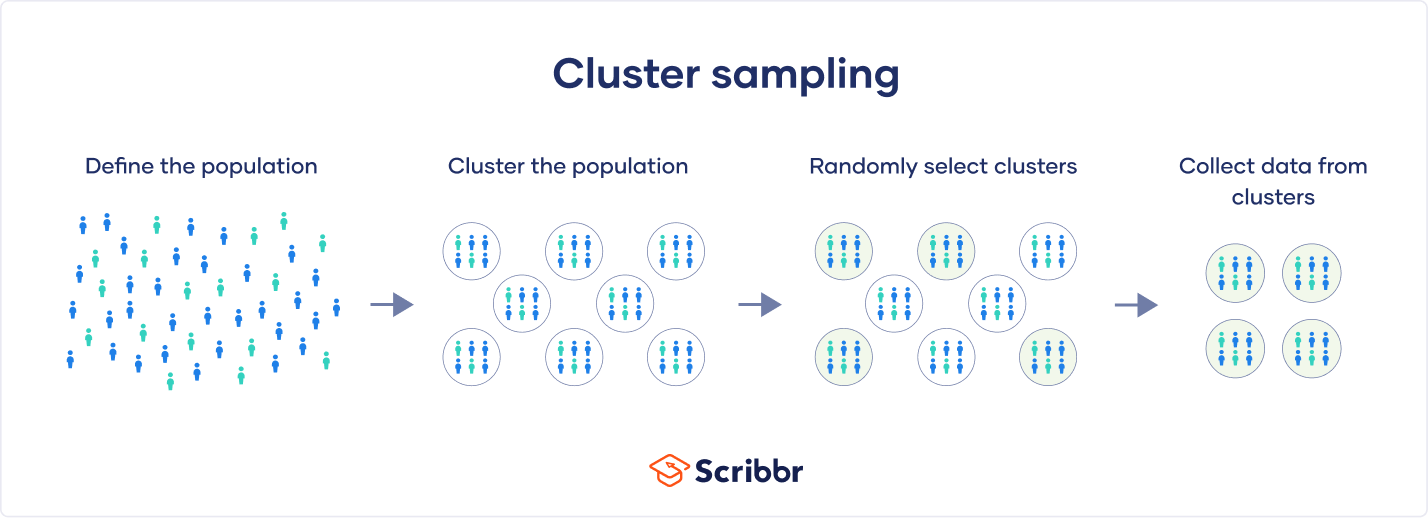
In cluster sampling, researchers divide a population into smaller groups known as clusters. They then randomly select among these clusters to form a sample.
Cluster sampling is a method of probability sampling that is often used to study large populations, particularly those that are widely geographically dispersed. Researchers usually use pre-existing units such as schools or cities as their clusters.
Published on
August 28, 2020
by
Lauren Thomas.
Revised on
December 18, 2023.
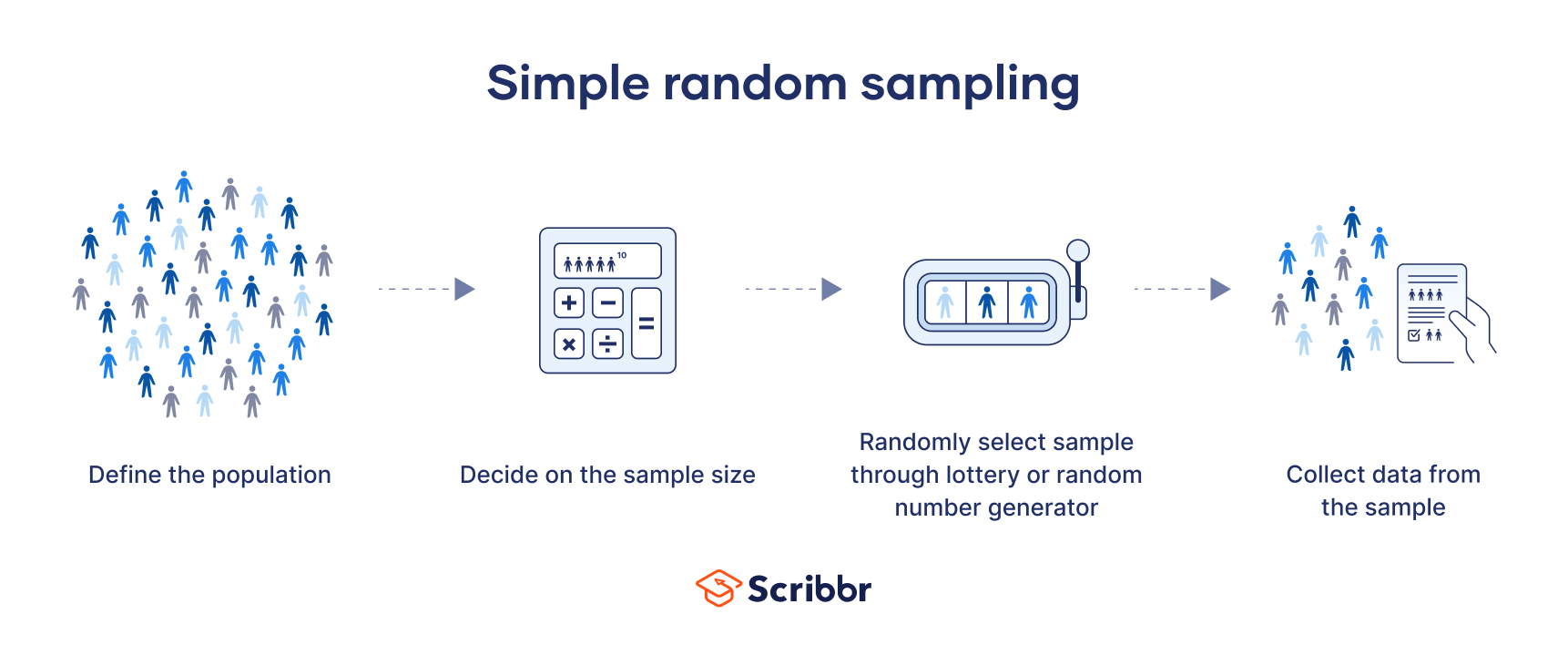
A simple random sample is a randomly selected subset of a population. In this sampling method, each member of the population has an exactly equal chance of being selected.
This method is the most straightforward of all the probability sampling methods, since it only involves a single random selection and requires little advance knowledge about the population. Because it uses randomization, any research performed on this sample should have high internal and external validity, and be at a lower risk for research biases like sampling bias and selection bias.
ExampleThe American Community Survey (ACS) uses simple random sampling. Officials from the United States Census Bureau follow a random selection of individual inhabitants of the United States for a year, asking detailed questions about their lives in order to draw conclusions about the whole population of the US.
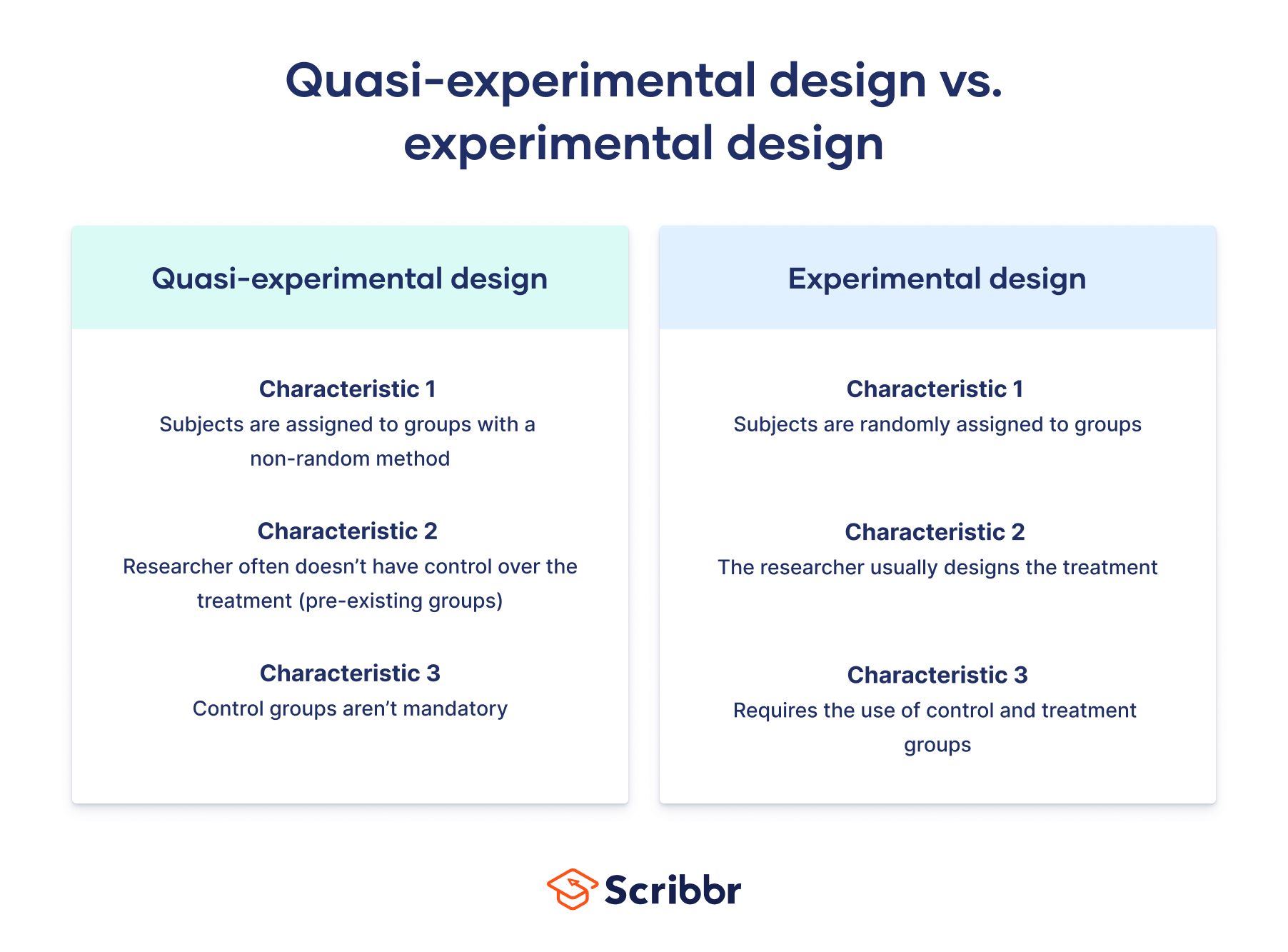
However, unlike a true experiment, a quasi-experiment does not rely on random assignment. Instead, subjects are assigned to groups based on non-random criteria.
Quasi-experimental design is a useful tool in situations where true experiments cannot be used for ethical or practical reasons.
Published on
July 10, 2020
by
Lauren Thomas.
Revised on
June 22, 2023.
In experimental research, subjects are randomly assigned to either a treatment or control group. A double-blind study withholds each subject’s group assignment from both the participant and the researcher performing the experiment.
Conversely, if researchers know which group a participant is assigned to, they might act in a way that reveals the assignment or directly influences the results. This can also lead to biases, particularly observer bias.
Double blinding guards against these risks, ensuring that any difference between the groups can be attributed to the treatment.