Guide to Experimental Design | Overview, 5 steps & Examples
Experiments are used to study causal relationships. You manipulate one or more independent variables and measure their effect on one or more dependent variables.
Experimental design create a set of procedures to systematically test a hypothesis. A good experimental design requires a strong understanding of the system you are studying.
There are five key steps in designing an experiment:
- Consider your variables and how they are related
- Write a specific, testable hypothesis
- Design experimental treatments to manipulate your independent variable
- Assign subjects to groups, either between-subjects or within-subjects
- Plan how you will measure your dependent variable
For valid conclusions, you also need to select a representative sample and control any extraneous variables that might influence your results. If random assignment of participants to control and treatment groups is impossible, unethical, or highly difficult, consider an observational study instead. This minimizes several types of research bias, particularly sampling bias, survivorship bias, and attrition bias as time passes.
Step 1: Define your variables
You should begin with a specific research question. We will work with two research question examples, one from health sciences and one from ecology:
To translate your research question into an experimental hypothesis, you need to define the main variables and make predictions about how they are related.
Start by simply listing the independent and dependent variables.
| Research question | Independent variable | Dependent variable |
|---|---|---|
| Phone use and sleep | Minutes of phone use before sleep | Hours of sleep per night |
| Temperature and soil respiration | Air temperature just above the soil surface | CO2 respired from soil |
Then you need to think about possible extraneous and confounding variables and consider how you might control them in your experiment.
| Extraneous variable | How to control | |
|---|---|---|
| Phone use and sleep | Natural variation in sleep patterns among individuals. | Control statistically: measure the average difference between sleep with phone use and sleep without phone use rather than the average amount of sleep per treatment group. |
| Temperature and soil respiration | Soil moisture also affects respiration, and moisture can decrease with increasing temperature. | Control experimentally: monitor soil moisture and add water to make sure that soil moisture is consistent across all treatment plots. |
Finally, you can put these variables together into a diagram. Use arrows to show the possible relationships between variables and include signs to show the expected direction of the relationships.
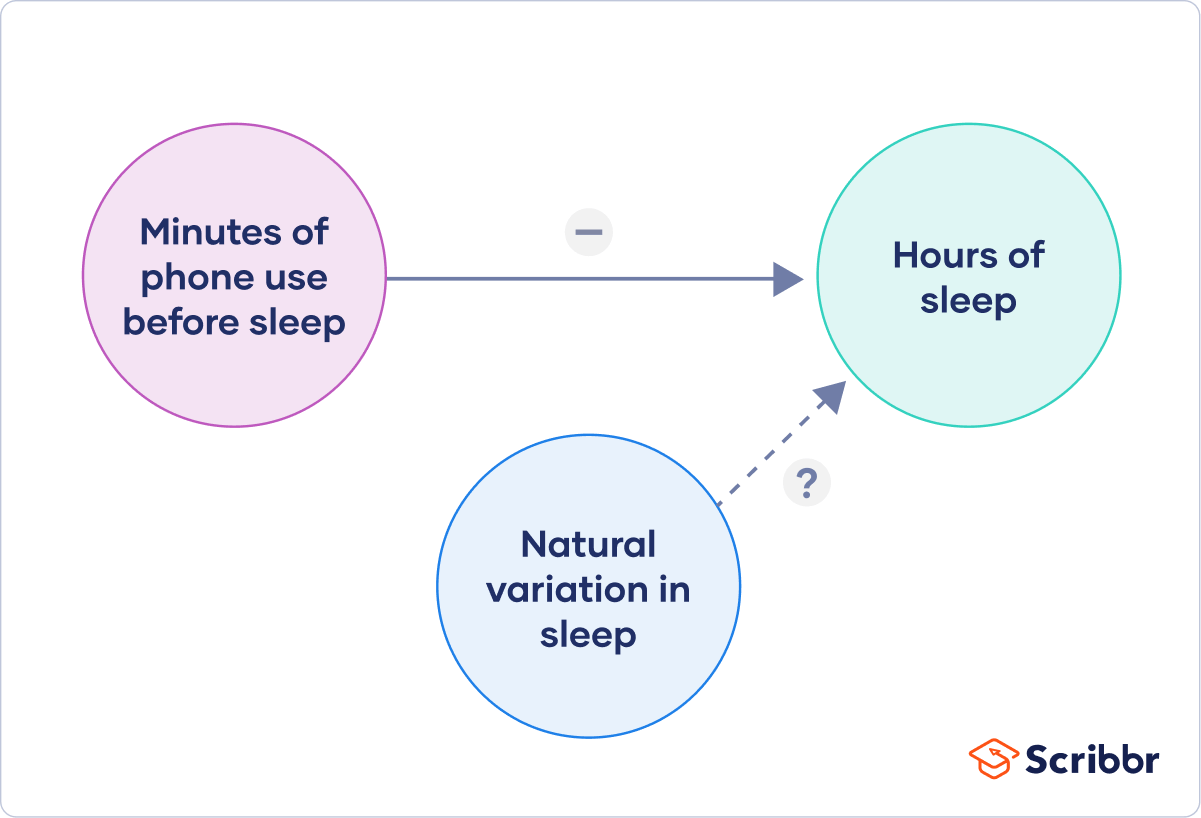
Here we predict that the amount of phone use will have a negative effect on hours of sleep, and predict an unknown influence of natural variation on hours of sleep.
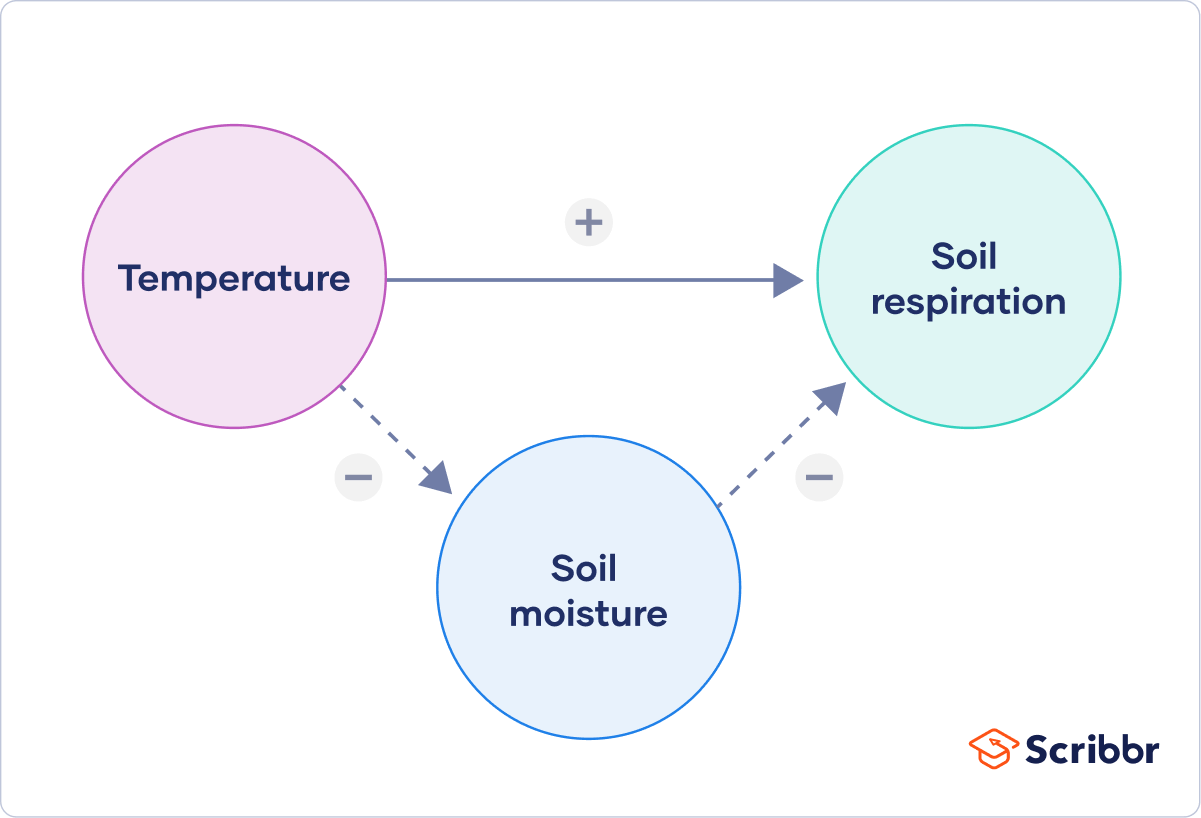
Here we predict that increasing temperature will increase soil respiration and decrease soil moisture, while decreasing soil moisture will lead to decreased soil respiration.
Step 2: Write your hypothesis
Now that you have a strong conceptual understanding of the system you are studying, you should be able to write a specific, testable hypothesis that addresses your research question.
| Null hypothesis (H0) | Alternate hypothesis (H1) | |
|---|---|---|
| Phone use and sleep | Phone use before sleep does not correlate with the amount of sleep a person gets. | Increasing phone use before sleep leads to a decrease in sleep. |
| Temperature and soil respiration | Air temperature does not correlate with soil respiration. | Increased air temperature leads to increased soil respiration. |
The next steps will describe how to design a controlled experiment. In a controlled experiment, you must be able to:
- Systematically and precisely manipulate the independent variable(s).
- Precisely measure the dependent variable(s).
- Control any potential confounding variables.
If your study system doesn’t match these criteria, there are other types of research you can use to answer your research question.
Step 3: Design your experimental treatments
How you manipulate the independent variable can affect the experiment’s external validity – that is, the extent to which the results can be generalized and applied to the broader world.
First, you may need to decide how widely to vary your independent variable.
- just slightly above the natural range for your study region.
- over a wider range of temperatures to mimic future warming.
- over an extreme range that is beyond any possible natural variation.
Second, you may need to choose how finely to vary your independent variable. Sometimes this choice is made for you by your experimental system, but often you will need to decide, and this will affect how much you can infer from your results.
- a categorical variable: either as binary (yes/no) or as levels of a factor (no phone use, low phone use, high phone use).
- a continuous variable (minutes of phone use measured every night).
Step 4: Assign your subjects to treatment groups
How you apply your experimental treatments to your test subjects is crucial for obtaining valid and reliable results.
First, you need to consider the study size: how many individuals will be included in the experiment? In general, the more subjects you include, the greater your experiment’s statistical power, which determines how much confidence you can have in your results.
Then you need to randomly assign your subjects to treatment groups. Each group receives a different level of the treatment (e.g. no phone use, low phone use, high phone use).
You should also include a control group, which receives no treatment. The control group tells us what would have happened to your test subjects without any experimental intervention.
When assigning your subjects to groups, there are two main choices you need to make:
- A completely randomized design vs a randomized block design.
- A between-subjects design vs a within-subjects design.
Randomization
An experiment can be completely randomized or randomized within blocks (aka strata):
- In a completely randomized design, every subject is assigned to a treatment group at random.
- In a randomized block design (aka stratified random design), subjects are first grouped according to a characteristic they share, and then randomly assigned to treatments within those groups.
| Completely randomized design | Randomized block design | |
|---|---|---|
| Phone use and sleep | Subjects are all randomly assigned a level of phone use using a random number generator. | Subjects are first grouped by age, and then phone use treatments are randomly assigned within these groups. |
| Temperature and soil respiration | Warming treatments are assigned to soil plots at random by using a number generator to generate map coordinates within the study area. | Soils are first grouped by average rainfall, and then treatment plots are randomly assigned within these groups. |
Sometimes randomization isn’t practical or ethical, so researchers create partially-random or even non-random designs. An experimental design where treatments aren’t randomly assigned is called a quasi-experimental design.
Between-subjects vs. within-subjects
In a between-subjects design (also known as an independent measures design or classic ANOVA design), individuals receive only one of the possible levels of an experimental treatment.
In medical or social research, you might also use matched pairs within your between-subjects design to make sure that each treatment group contains the same variety of test subjects in the same proportions.
In a within-subjects design (also known as a repeated measures design), every individual receives each of the experimental treatments consecutively, and their responses to each treatment are measured.
Within-subjects or repeated measures can also refer to an experimental design where an effect emerges over time, and individual responses are measured over time in order to measure this effect as it emerges.
Counterbalancing (randomizing or reversing the order of treatments among subjects) is often used in within-subjects designs to ensure that the order of treatment application doesn’t influence the results of the experiment.
| Between-subjects (independent measures) design | Within-subjects (repeated measures) design | |
|---|---|---|
| Phone use and sleep | Subjects are randomly assigned a level of phone use (none, low, or high) and follow that level of phone use throughout the experiment. | Subjects are assigned consecutively to zero, low, and high levels of phone use throughout the experiment, and the order in which they follow these treatments is randomized. |
| Temperature and soil respiration | Warming treatments are assigned to soil plots at random and the soils are kept at this temperature throughout the experiment. | Every plot receives each warming treatment (1, 3, 5, 8, and 10C above ambient temperatures) consecutively over the course of the experiment, and the order in which they receive these treatments is randomized. |
Step 5: Measure your dependent variable
Finally, you need to decide how you’ll collect data on your dependent variable outcomes. You should aim for reliable and valid measurements that minimize research bias or error.
Some variables, like temperature, can be objectively measured with scientific instruments. Others may need to be operationalized to turn them into measurable observations.
- Ask participants to record what time they go to sleep and get up each day.
- Ask participants to wear a sleep tracker.
How precisely you measure your dependent variable also affects the kinds of statistical analysis you can use on your data.
Experiments are always context-dependent, and a good experimental design will take into account all of the unique considerations of your study system to produce information that is both valid and relevant to your research question.
Other interesting articles
If you want to know more about statistics, methodology, or research bias, make sure to check out some of our other articles with explanations and examples.
Statistics
Methodology
Frequently asked questions about experiments
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bevans, R. (2023, June 21). Guide to Experimental Design | Overview, 5 steps & Examples. Scribbr. Retrieved July 9, 2026, from https://www.scribbr.com/methodology/experimental-design/
