How to Calculate Standard Deviation (Guide) | Calculator & Examples
The standard deviation is the average amount of variability in your dataset. It tells you, on average, how far each value lies from the mean.
A high standard deviation means that values are generally far from the mean, while a low standard deviation indicates that values are clustered close to the mean.
Table of contents
- What does standard deviation tell you?
- Standard deviation formulas for populations and samples
- Standard deviation calculator
- Steps for calculating the standard deviation by hand
- Why is standard deviation a useful measure of variability?
- Other interesting articles
- Frequently asked questions about standard deviation
What does standard deviation tell you?
Standard deviation is a useful measure of spread for normal distributions.
In normal distributions, data is symmetrically distributed with no skew. Most values cluster around a central region, with values tapering off as they go further away from the center. The standard deviation tells you how spread out from the center of the distribution your data is on average.
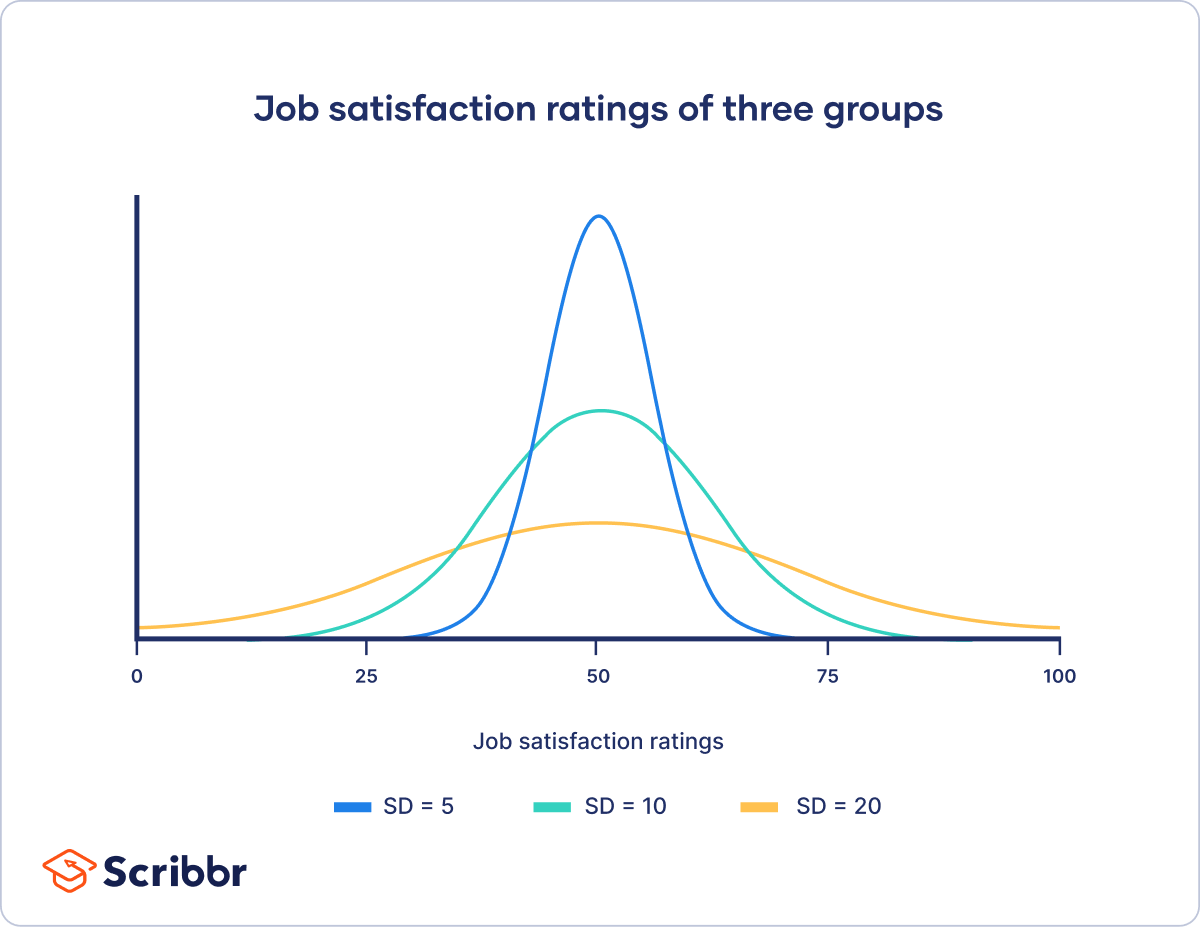
Many scientific variables follow normal distributions, including height, standardized test scores, or job satisfaction ratings. When you have the standard deviations of different samples, you can compare their distributions using statistical tests to make inferences about the larger populations they came from.
The mean (M) ratings are the same for each group – it’s the value on the x-axis when the curve is at its peak. However, their standard deviations (SD) differ from each other.
The standard deviation reflects the dispersion of the distribution. The curve with the lowest standard deviation has a high peak and a small spread, while the curve with the highest standard deviation is more flat and widespread.
The empirical rule
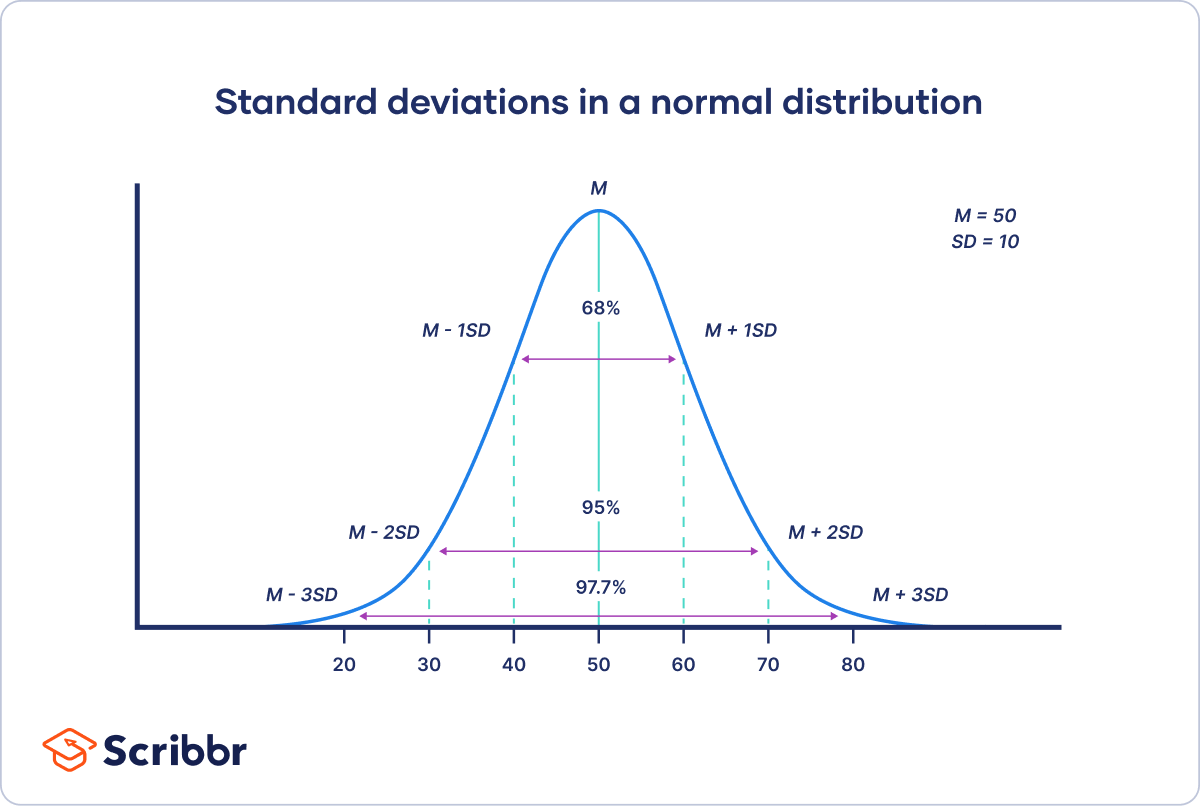
The standard deviation and the mean together can tell you where most of the values in your frequency distribution lie if they follow a normal distribution.
The empirical rule, or the 68-95-99.7 rule, tells you where your values lie:
- Around 68% of scores are within 1 standard deviation of the mean,
- Around 95% of scores are within 2 standard deviations of the mean,
- Around 99.7% of scores are within 3 standard deviations of the mean.
Following the empirical rule:
- Around 68% of scores are between 40 and 60.
- Around 95% of scores are between 30 and 70.
- Around 99.7% of scores are between 20 and 80.
The empirical rule is a quick way to get an overview of your data and check for any outliers or extreme values that don’t follow this pattern.
Standard deviation formulas for populations and samples
Different formulas are used for calculating standard deviations depending on whether you have collected data from a whole population or a sample.
Population standard deviation
When you have collected data from every member of the population that you’re interested in, you can get an exact value for population standard deviation.
The population standard deviation formula looks like this:
| Formula | Explanation |
|---|---|
 |
|
 = population standard deviation
= population standard deviation = sum of…
= sum of… = each value
= each value = population mean
= population mean = number of values in the population
= number of values in the populationSample standard deviation
When you collect data from a sample, the sample standard deviation is used to make estimates or inferences about the population standard deviation.
The sample standard deviation formula looks like this:
| Formula | Explanation |
|---|---|
 |
|
 = sample standard deviation
= sample standard deviation = sample mean
= sample mean = number of values in the sample
= number of values in the sampleWith samples, we use n – 1 in the formula because using n would give us a biased estimate that consistently underestimates variability. The sample standard deviation would tend to be lower than the real standard deviation of the population.
Reducing the sample n to n – 1 makes the standard deviation artificially large, giving you a conservative estimate of variability.
While this is not an unbiased estimate, it is a less biased estimate of standard deviation: it is better to overestimate rather than underestimate variability in samples.
Standard deviation calculator
You can calculate the standard deviation by hand or with the help of our standard deviation calculator below.
Steps for calculating the standard deviation by hand
The standard deviation is usually calculated automatically by whichever software you use for your statistical analysis. But you can also calculate it by hand to better understand how the formula works.
There are six main steps for finding the standard deviation by hand. We’ll use a small data set of 6 scores to walk through the steps.
| Data set | |||||
|---|---|---|---|---|---|
| 46 | 69 | 32 | 60 | 52 | 41 |
Step 1: Find the mean
To find the mean, add up all the scores, then divide them by the number of scores.
| Mean (x̅) |
|---|
 |
Step 2: Find each score’s deviation from the mean
Subtract the mean from each score to get the deviations from the mean.
Since x̅ = 50, here we take away 50 from each score.
| Score | Deviation from the mean |
|---|---|
| 46 | 46 – 50 = -4 |
| 69 | 69 – 50 = 19 |
| 32 | 32 – 50 = -18 |
| 60 | 60 – 50 = 10 |
| 52 | 52 – 50 = 2 |
| 41 | 41 – 50 = -9 |
Step 3: Square each deviation from the mean
Multiply each deviation from the mean by itself. This will result in positive numbers.
| Squared deviations from the mean |
|---|
| (-4)2 = 4 × 4 = 16 |
| 192 = 19 × 19 = 361 |
| (-18)2 = -18 × -18 = 324 |
| 102 = 10 × 10 = 100 |
| 22 = 2 × 2 = 4 |
| (-9)2 = -9 × -9 = 81 |
Step 4: Find the sum of squares
Add up all of the squared deviations. This is called the sum of squares.
| Sum of squares |
|---|
| 16 + 361 + 324 + 100 + 4 + 81 = 886 |
Step 5: Find the variance
Divide the sum of the squares by n – 1 (for a sample) or N (for a population) – this is the variance.
Since we’re working with a sample size of 6, we will use n – 1, where n = 6.
| Variance |
|---|
 |
Step 6: Find the square root of the variance
To find the standard deviation, we take the square root of the variance.
| Standard deviation |
|---|
 |
From learning that SD = 13.31, we can say that each score deviates from the mean by 13.31 points on average.
Why is standard deviation a useful measure of variability?
Although there are simpler ways to calculate variability, the standard deviation formula weighs unevenly spread out samples more than evenly spread samples. A higher standard deviation tells you that the distribution is not only more spread out, but also more unevenly spread out.
This means it gives you a better idea of your data’s variability than simpler measures, such as the mean absolute deviation (MAD).
The MAD is similar to standard deviation but easier to calculate. First, you express each deviation from the mean in absolute values by converting them into positive numbers (for example, -3 becomes 3). Then, you calculate the mean of these absolute deviations.
Unlike the standard deviation, you don’t have to calculate squares or square roots of numbers for the MAD. However, for that reason, it gives you a less precise measure of variability.
Let’s take two samples with the same central tendency but different amounts of variability. Sample B is more variable than Sample A.
| Values | Mean | Mean absolute deviation | Standard deviation | |
|---|---|---|---|---|
| Sample A | 66, 30, 40, 64 | 50 | 15 | 17.8 |
| Sample B | 51, 21, 79, 49 | 50 | 15 | 23.7 |
For samples with equal average deviations from the mean, the MAD can’t differentiate levels of spread. The standard deviation is more precise: it is higher for the sample with more variability in deviations from the mean.
By squaring the differences from the mean, standard deviation reflects uneven dispersion more accurately. This step weighs extreme deviations more heavily than small deviations.
However, this also makes the standard deviation sensitive to outliers.
Other interesting articles
If you want to know more about statistics, methodology, or research bias, make sure to check out some of our other articles with explanations and examples.
Statistics
Methodology
Frequently asked questions about standard deviation
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2024, March 28). How to Calculate Standard Deviation (Guide) | Calculator & Examples. Scribbr. Retrieved July 1, 2026, from https://www.scribbr.com/statistics/standard-deviation/
