Published on
September 19, 2022
by
Rebecca Bevans.
Revised on
June 21, 2023.
In statistical research, a variable is defined as an attribute of an object of study. Choosing which variables to measure is central to good experimental design.
Example
If you want to test whether some plant species are more salt-tolerant than others, some key variables you might measure include the amount of salt you add to the water, the species of plants being studied, and variables related to plant health like growth and wilting.
You need to know which types of variables you are working with in order to choose appropriate statistical tests and interpret the results of your study.
You can usually identify the type of variable by asking two questions:
Published on
August 28, 2020
by
Rebecca Bevans.
Revised on
June 21, 2023.
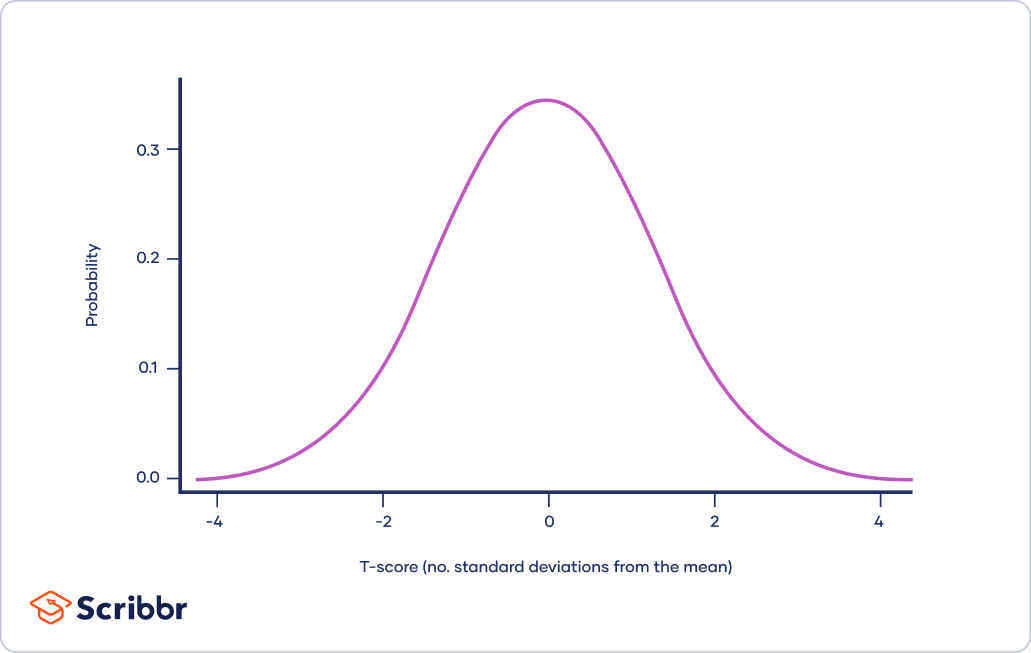
The t-distribution, also known as Student’s t-distribution, is a way of describing data that follow a bell curve when plotted on a graph, with the greatest number of observations close to the mean and fewer observations in the tails.
It is a type of normal distribution used for smaller sample sizes, where the variance in the data is unknown.
In statistics, the t-distribution is most often used to:
Find the critical values for a confidence interval when the data is approximately normally distributed.
Published on
August 7, 2020
by
Rebecca Bevans.
Revised on
June 22, 2023.
When you make an estimate in statistics, whether it is a summary statistic or a test statistic, there is always uncertainty around that estimate because the number is based on a sample of the population you are studying.
The confidence interval is the range of values that you expect your estimate to fall between a certain percentage of the time if you run your experiment again or re-sample the population in the same way.
The confidence level is the percentage of times you expect to reproduce an estimate between the upper and lower bounds of the confidence interval, and is set by the alpha value.
Published on
July 17, 2020
by
Rebecca Bevans.
Revised on
June 22, 2023.
The test statistic is a number calculated from a statistical test of a hypothesis. It shows how closely your observed data match the distribution expected under the null hypothesis of that statistical test.
The test statistic is used to calculate the p value of your results, helping to decide whether to reject your null hypothesis.
Published on
July 16, 2020
by
Rebecca Bevans.
Revised on
June 22, 2023.
The p value is a number, calculated from a statistical test, that describes how likely you are to have found a particular set of observations if the null hypothesis were true.
P values are used in hypothesis testing to help decide whether to reject the null hypothesis. The smaller the p value, the more likely you are to reject the null hypothesis.
Published on
March 26, 2020
by
Rebecca Bevans.
Revised on
June 22, 2023.
The Akaike information criterion (AIC) is a mathematical method for evaluating how well a model fits the data it was generated from. In statistics, AIC is used to compare different possible models and determine which one is the best fit for the data. AIC is calculated from:
the maximum likelihood estimate of the model (how well the model reproduces the data).
The best-fit model according to AIC is the one that explains the greatest amount of variation using the fewest possible independent variables.
Akaike information criterion exampleYou want to know whether drinking sugar-sweetened beverages influences body weight. You have collected secondary data from a national health survey that contains observations on sugar-sweetened beverage consumption, age, sex, and BMI (body mass index).
To find out which of these variables are important for predicting the relationship between sugar-sweetened beverage consumption and body weight, you create several possible models and compare them using AIC.
Published on
March 20, 2020
by
Rebecca Bevans.
Revised on
June 22, 2023.
ANOVA (Analysis of Variance) is a statistical test used to analyze the difference between the means of more than two groups.
A two-way ANOVA is used to estimate how the mean of a quantitative variable changes according to the levels of two categorical variables. Use a two-way ANOVA when you want to know how two independent variables, in combination, affect a dependent variable.
ExampleYou are researching which type of fertilizer and planting density produces the greatest crop yield in a field experiment. You assign different plots in a field to a combination of fertilizer type (1, 2, or 3) and planting density (1=low density, 2=high density), and measure the final crop yield in bushels per acre at harvest time.
You can use a two-way ANOVA to find out if fertilizer type and planting density have an effect on average crop yield.
One-way ANOVA exampleAs a crop researcher, you want to test the effect of three different fertilizer mixtures on crop yield. You can use a one-way ANOVA to find out if there is a difference in crop yields between the three groups.
Published on
March 6, 2020
by
Rebecca Bevans.
Revised on
June 22, 2023.
ANOVA is a statistical test for estimating how a quantitative dependent variable changes according to the levels of one or more categorical independent variables. ANOVA tests whether there is a difference in means of the groups at each level of the independent variable.
The null hypothesis (H0) of the ANOVA is no difference in means, and the alternative hypothesis (Ha) is that the means are different from one another.
In this guide, we will walk you through the process of a one-way ANOVA (one independent variable) and a two-way ANOVA (two independent variables).
Our sample dataset contains observations from an imaginary study of the effects of fertilizer type and planting density on crop yield.
One-way ANOVA exampleIn the one-way ANOVA, we test the effects of 3 types of fertilizer on crop yield.Two-way ANOVA exampleIn the two-way ANOVA, we add an additional independent variable: planting density. We test the effects of 3 types of fertilizer and 2 different planting densities on crop yield.
We will also include examples of how to perform and interpret a two-way ANOVA with an interaction term, and an ANOVA with a blocking variable.
Published on
February 25, 2020
by
Rebecca Bevans.
Revised on
May 10, 2024.
Linear regression is a regression model that uses a straight line to describe the relationship between variables. It finds the line of best fit through your data by searching for the value of the regression coefficient(s) that minimizes the total error of the model.
In this step-by-step guide, we will walk you through linear regression in R using two sample datasets.
Simple linear regressionThe first dataset contains observations about income (in a range of $15k to $75k) and happiness (rated on a scale of 1 to 10) in an imaginary sample of 500 people. The income values are divided by 10,000 to make the income data match the scale of the happiness scores (so a value of $2 represents $20,000, $3 is $30,000, etc.)Multiple linear regressionThe second dataset contains observations on the percentage of people biking to work each day, the percentage of people smoking, and the percentage of people with heart disease in an imaginary sample of 500 towns.